Redis数据结构与对象
一、简单动态字符串
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组),而是自己构建了一种名为简单动态字符串(SDS)的抽象类型。
1.1SDS的定义
struct sdshdr{
//记录buf数组已使用字节的数量,等于SDS保存字符串的长度
int len;
//记录buf数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf[];
}
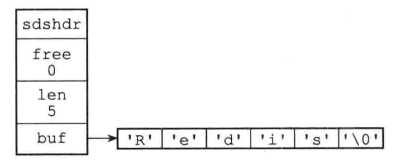
SDS遵循C字符串以空字符结尾的惯例,遵循空字符结尾的好处是,SDS可以直接重用一部分C字符串函数库里面的函数。
1.2SDS与C字符串的区别
①通过len属性,SDS能以常数复杂度获取,而C字符串需要变量,时间复杂度为O(1);
②杜绝缓冲区溢出,SDS在调用改变字符串长度的函数时,会自动检查数组长度,是否够用,进行再分配;而C语言如果没有进行空间检查,很容易造成溢出问题;
③减少修改字符串时带来的内存重分配次数,SDS实现了空间预分配和惰性空间释放两种优化策略。空间预分配:如果SDS字符串修改后,总空间小于1M,那么预分配一倍的空间,如果大于1M,则默认预分配1M。惰性空间:如果添加的字符串小于free的空间,则不会进行空间重分配;
④二进制安全,C字符串除了末尾的空字符,不允许其他地方包含空字符,而SDS没有限制,可以保存任意形式的数据;这也是SDS的buf属性称为字节数组的原因,Redis不是用这个数据来保存字符,而是来保存二进制数据;
二、链表
链表提供了高效的节点重拍能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度;
2.1链表和链表节点的实现
typedef struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
}listNode;
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned longlen;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值对比函数
int (*match)(void *ptr,void *key);
}list;

Redis使用list来持有链表,多个listNode可以通过prev和next指针组成双端链表;
三、字典
3.1字典的实现
Redis的字典使用哈希表作为底层实现,一个哈希表可以有多个哈希节点,而每个哈希表节点就保存了字典中的一个键值对;
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值,总是等于size-1
unsigned long sizemask;
//该哈希表已有节点的数量;
unsigned long used;
}dictht;
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry;
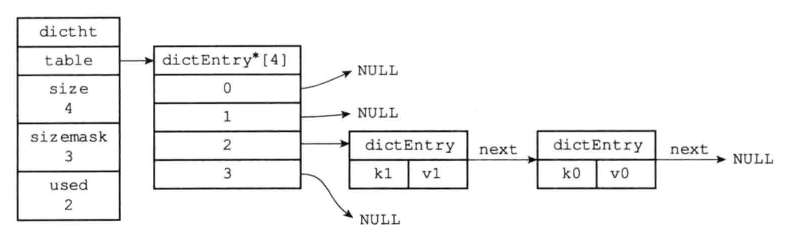
table属性是一个数组,数组中每个元素都指向dictEntry结构的指针;dictEntry结构中保存着一个键值对,key属性保存着键值对中的健,而V属性则保存着键值对中的值。
typedef struct dict{
//类型特定函数
dictType *type;
//私有数据
void *privdata;
dictht ht[2];
//rehash索引,当rehash不在进行时,值为-1
in trehashidx;/*rehashing not in progress if rehashidx==-1 */
}
typedef struct dictType{
//计算hash值得函数
unsighed int (*hashFunction)(const void *key);
//复制键的函数
void *(*keyDup)(void *privdata,const void *key);
//复制值得函数
void *(*valDup)(void *privdata,const void *obj);
//对比键的函数
int (*keyCompare)(void *privdata,const void *key1,const void *key2);
//销毁键的函数
void (*keyDestructor)(void *privdata,void *key);
//销毁值得函数
void (*valDestructor)(void *privdate,void *obj);
}
ht属性是包含两个项得数组,每个项都是一个dictht哈希表,一般情况下,字典只使用ht[0]哈希表,ht[1]只会在rehash时使用。
3.2哈希算法
当要将一个新的键值对添加到字典里面时,需要先根据键值对的键计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组指定索引上面。
3.3解决键冲突
当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时,我们称这些键发生了冲突;
Redis的哈希表使用链地址法,来解决键冲突,每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,这就解决了键冲突的问题。
因为dictEntry节点组成的链表没有指向链表表尾的指针,所以为了速度考虑,程序总是将节点添加到链表的表头位置(复杂度为O(1));
3.4rehash
随着哈希表键值对的不断增多或者减少,为了让哈希表的负载因子维持在一个合理的范围之内,哈希表需要扩展或者收缩,redis通过rehash来完成操作:
①为字典ht[1]哈希表分配空间,这个空间的大小为2的次方幂;
②将保存在ht[0]中的所有键值对rehash到ht[1]上面:rehash指的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上;
③当ht[0]包含的所有键值对都迁移到ht[1]之后(ht[0]变成空表),释放ht[0],将ht[1]设置为ht[0],并在ht[1]新建一个空白哈希表。
3.5渐进式rehash
扩展或收缩哈希表需要将ht[0]里面的所有键值对rehash到ht[1]里面,但是,这个动作是分多次、渐进式地完成;
这样是为了避免ht[0]中大量地数据导致服务器长时间地暂停服务;
在rehash期间,会将rehashidx的值设置为0,表示rehash工作正式开始;每次对字典执行添加、删除、查找或者更新操作,程序会先在ht[0]中查找,如果没找到的话,就会继续到ht[1]里面查找。
四、跳跃表
跳跃表是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的;
4.1跳跃表的实现
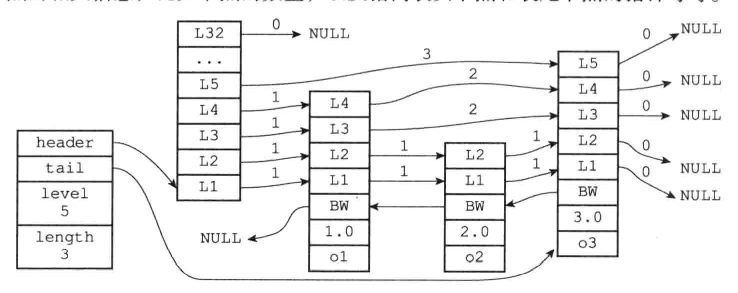
header:指向跳跃表的表头节点
tail:指向跳跃表的表尾节点
level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)
length:记录跳跃表的长度
跳跃表的节点:
typedef struct zskiplistNode{
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
}level[];
//后退指针
struct zskiplistNode *backwarf;
//分值
double score;
//成员对象
robj *obj;
}zskiplistNode;
跳跃表持有:
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header,*tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;
五、整数集合
整数集合是集合键的底层实现之一;
5.1整数集合的实现
typedef struct intset{
//编码方式
unit32_t encoding;
//集合包含的元素数量
unit32_t length;
//保存元素的数组
int8_t contents[];
}intset;
整数集合中,数据的encoding值取决于实际存放数据。根据存放值的范围不同,会使用int8_t、int16_t、int32_t、int64_t的编码类型;
每当我们要将一个新元素添加到整数集合中,并且新元素的类型比整数集合现有所有元素的类型都要长时,整数集合需要升级,然后才能将新元素添加到整数集合中(整合集合中的encoding保持一致)。
六、压缩列表
当一个列表键只包含少量列表项,并且每个列表项要么是较小的整数值,要么是比较短的字符串,那么Redis底层就会用压缩列表来实现。
6.1压缩列表的构成

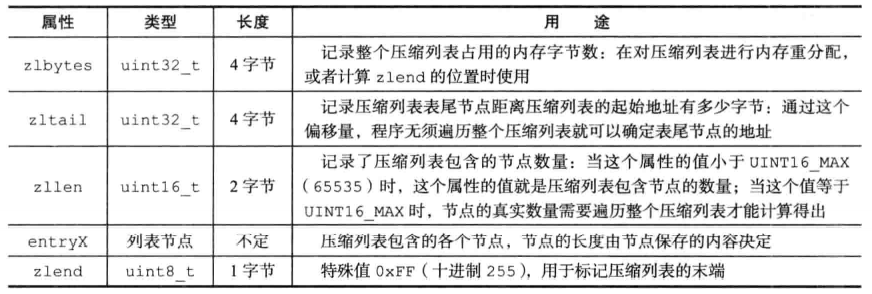
6.2压缩列表节点的构成

previous_entry_length属性以字节为单位,记录了压缩列表中前一个节点的长度;
encoding记录了节点保存的数据类型和长度;
content负责保存节点的值;
七、对象
简单动态字符串、链表、字典、跳跃表、整数集合、压缩列表等等,都是Redis的主要数据结构,但是Redis并没有直接使用这些数据结构来时间键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,每种对象都用到了至少一种前面介绍的数据结构。
通过这5种类型的对象,Redis可以在执行命令前,根据类型判断是否可执行;而且根据不同的场景,选择不同的底层数据结构,优化使用效率;我的理解是,对象是用户层面的,用户选择不同的对象类型来进行存储,在满足需求的情况下,越少操作越简单越方便,底层数据结构是系统层面的,目的是提升效率,节约空间的;
Redis的对象系统还实现了基于引用计数技术的内存回收机制,当程序不在使用某个对象的时候,这个对象所占内存会被释放。
7.1对象的类型与编码
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层实现数据结构的指针
void *ptr;
//引用计数
int refcount;
//空转时长
unsigned lru:22;
//。。。
}robj;
7.2有序集合对象
为什么有序集合需要同时使用跳跃表和字典来实现?
理论上,有序集合可以单独使用字典或者跳跃表的其中一个数据结构来实现,结合使用,整合了优点,在性能上得到了提升;
查找时,通过字典,可以在O(1)复杂度找到对象,范围或者是排序是,跳跃表的效率会更高。
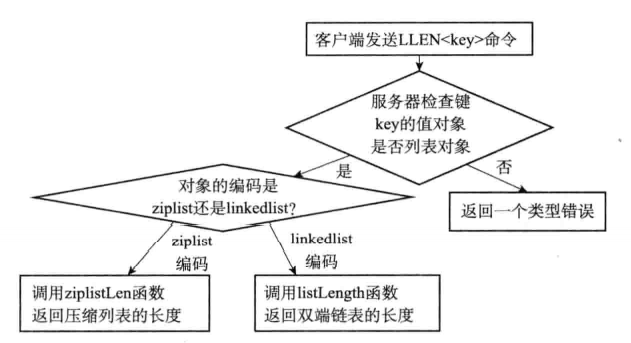
7.3类型检查与命令多态
7.4内存回收
Redis通过引用计数技术实现内存回收机制。在创建一个新对象时,引用计数的值会被初始化为1;对象被一个新程序使用时,引用计数值会增加1;当对象不再被引用时,计数减1;当计数为0时,对象内存会被释放;
7.4.1对象共享
对象的引用计数属性还带有对象共享的作用,当对象被共享时,对象的引用计数会增加1;另外共享对象不单单是字符串键可以使用,数据结构中嵌套的字符串也可以共享;
7.4.2为什么不共享包含字符串的对象?
当服务器考虑将一个共享对象设置为键的值对象时,程序需要检查给定的共享对象和键想创建的目标对象是否完全相同,只有完全相同,才能共享。而一个共享对象保存的值越复杂,验证对象是否相同消耗的时间越多;
因此,尽管共享更复杂的对象可以节省更多的内存,但受到CPU时间的限制,Redis只对包含整数值的字符串对象进行共享。
7.5对象的空转时长
该属性记录了对象最后一次被命令程序访问的时间,当服务器占用的内存数超过上限时,空转时长较高的那部分键会优先被服务器释放,回收内存。