创建高性能索引
一、索引的概念
索引(也叫做“key”),是存储引擎用于快速找到记录的一种数据结构;
索引可以包含一个或多个列的值,如果包含多个列,顺序很重要,因为MySQL只能高效地使用索引的最左前缀列;
1.1索引的实现原理
1.1.1B-Tree/B+Tree索引
B-Tree(多路平衡查找树)
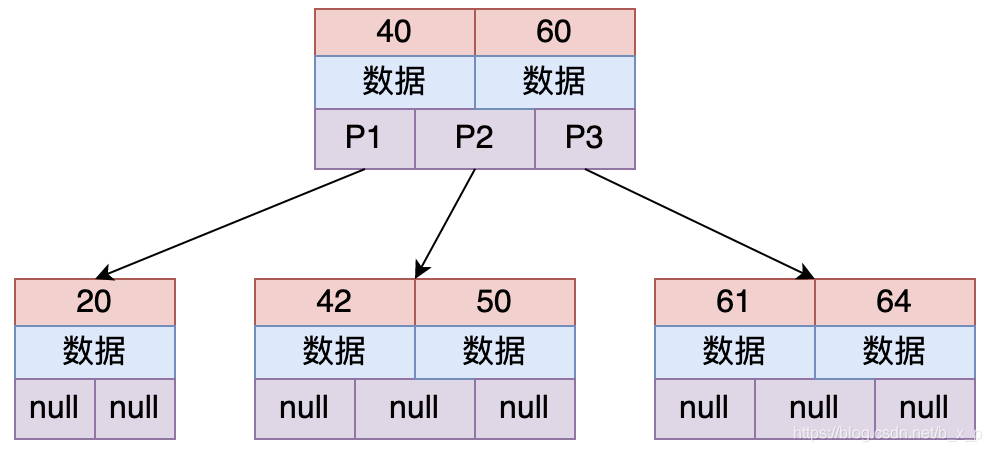
图为一个2-3树(每个节点存储2个关键字,有3路),多路平衡查找树也就是多叉的意思,从上图中可以看出,每个节点保存的关键字的个数和路数关系为:关键字个数 = 路数 – 1。
假设要从上图中查找id = X的数据,B-Tree搜索过程如下:
①取出根磁盘块,加载40和60两个关键字;
②如果X等于40,则命中;如果X小于40走P1;如果40 < X < 60走P2;如果X = 60,则命中;如果X > 60走P3;
③根据以上规则命中后,接下来加载对应的数据, 数据区中存储的是具体的数据或者是指向数据的指针。
**优点:**B-Tree很好的利用操作系统和磁盘的交互特性, MySQL为了很好的利用磁盘的预读能力,将页大小设置为16K,即将一个节点(磁盘块)的大小设置为16K,一次IO将一个节点(16K)内容加载进内存。
B+Tree
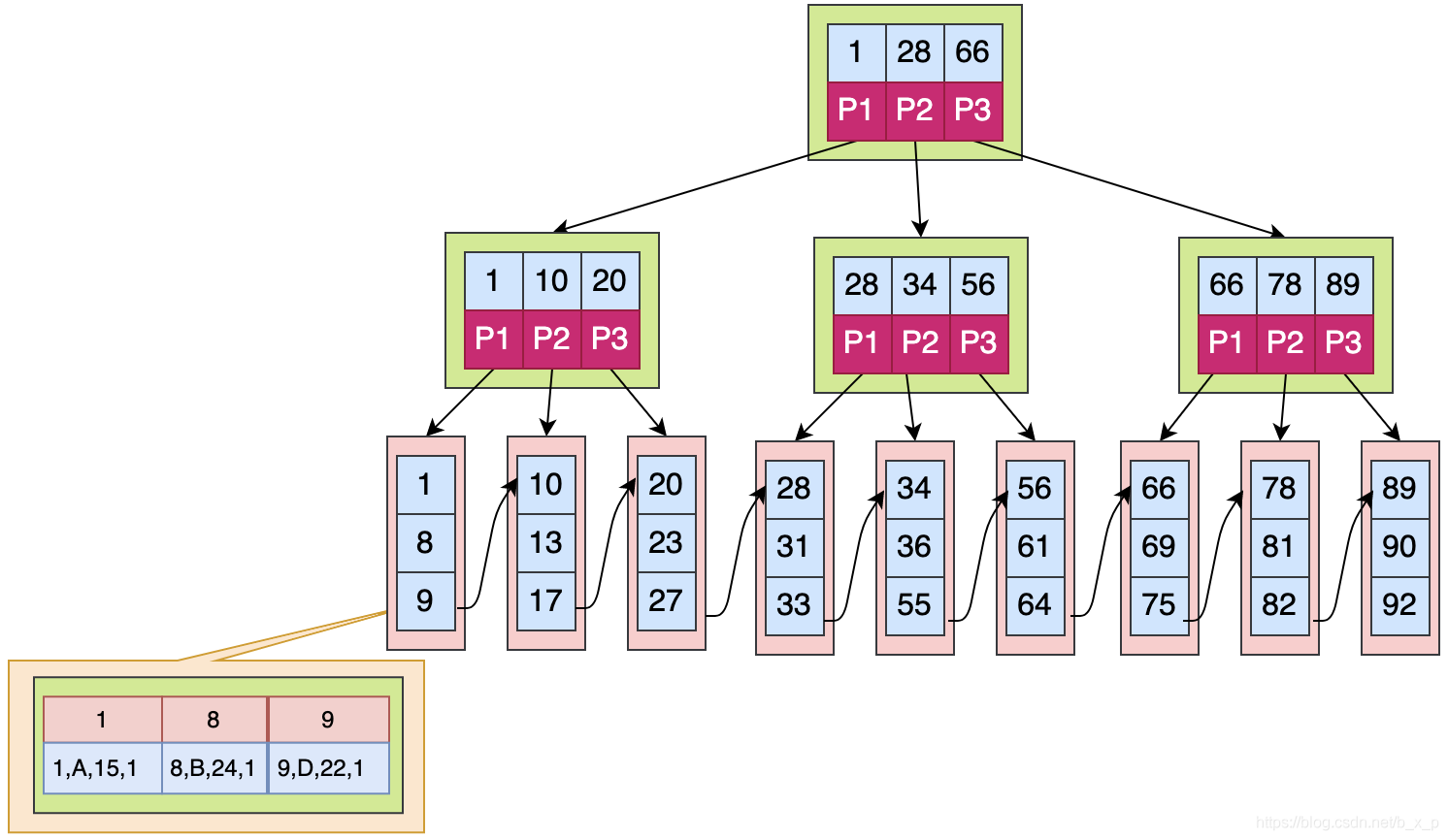
B+Tree是B-Tree的一个变种,在B+Tree中,B树的路数和关键字的个数的关系不再成立了,数据检索规则采用的是左闭合区间,路数和关键个数关系为1比1;
如果上图中是用ID做的索引,如果是搜索X = 1的数据,搜索规则如下:
①取出根磁盘块,加载1,28,66三个关键字。
②1<=X<=28, 走P1,取出磁盘块,加载1,10,20三个关键字;
③1<=X<=10, 走P1,取出磁盘块,加载1,8,9三个关键字;
④已经到达叶子节点,命中1,接下来加载对应的数据,图中数据区中存储的是具体的数据。
MySQL为什么最终要去选择B+Tree?
①B+Tree是B-Tree的变种,B TREE能解决的问题,B+TREE也能够解决(降低树的高度,增大节点存储数据量)
②B+Tree扫库和扫表能力更强。如果我们要根据索引去进行数据表的扫描,对B-Tree进行扫描,需要把整棵树遍历一遍,而B+Tree只需要遍历他的所有叶子节点即可(叶子节点之间有引用)。
③B+Tree磁盘读写能力更强。他的根节点和支节点不保存数据区,所以根节点和支节点同样大小的情况下,保存的关键字要比B-Tree要多。而叶子节点不保存子节点引用,能用于保存更多的关键字和数据。所以,B+Tree读写一次磁盘加载的关键字比B-Tree更多。
④B+Tree排序能力更强。上面的图中可以看出,B+Tree天然具有排序功能。
⑤B+Tree查询性能稳定。B+Tree数据只保存在叶子节点,每次查询数据,查询IO次数一定是稳定的。当然这个每个人的理解都不同,因为在B-Tree如果根节点命中直接返回,确实效率更高。
B-Tree/B+Tree索引特性
全值匹配:查找项跟索引全部匹配;
匹配最左前缀:最最最基本的特性!例如索引(a,b,c),可以匹配查询(a),(a,b),(a,b,c),其他均不行;
匹配列前缀:可以模糊查询(like “a%”),但是(like “%a"或者”%a%"),则无法使用索引,不符合最左前缀;
匹配范围值:可以匹配a的模糊查询(>,<,=,like),但是右边的查询失效,无法使用索引;
精准匹配某一列并范围匹配另外一列:基准查询a,范围查询b;
只访问索引的查询:覆盖索引;
PS:索引中的顺序很重要!!!
1.1.2哈希索引
哈希索引基于哈希表实现,只有精准匹配索引所有列的查询才有效。根据索引列的值,计算对应哈希值,保存至表中,查询时,通过哈希值精准匹配。
哈希索引特性
哈希索引只包含哈希值和行指针;
哈希索引不是按照索引顺序存储,无法用于排序;
不支持索引列单纯的查找;
不支持范围查找;
访问速度非常快,除非有很多哈希冲突;
创建自定义哈希索引
在B Tree基础上创建一个伪哈希索引。这和真正的哈希索引不是一回事,但是它使用哈希值而不是健本身进行索引查找。
例如,在一个数据表中,保存了大量url。直接保存url索引的话,因为字符串比较长,性能会比较差。可以通过新建一个列url_crc保存url的哈希值,通过新建url_crc的索引,来进行查询。
需要注意的是,因为存在hash冲突,所以需要将原url的查询条件一起查询,这样有利用的索引又保证了数据;
#在该案例中,可以通过触发器,执行保存url——crc哈希值的工作;
#在insert/update表中之前触发操作,具体操作通过set语句定义;
create trigger tri-name before insert on table for each row
set new.url_crc=crc32(new.url);
create trigger tri-name before update on table for each row
set new.url_crc=crc32(new.url);
1.1.3空间数据索引
MyISAM表支持空间索引,可以用作地理数据存储;
1.1.4全文索引
全文索引是一种特殊类型的索引,他查找的是文本中的关键词,而不是直接比较索引中的值;
1.2索引的优点
①索引大大的减少了服务器需要扫描的数据量;
②索引可以帮助服务器避免排序和临时表;
③索引可以将随机IO变成顺序IO;
二、高性能索引策略
2.1独立的列
如果查询的列不是独立的,则MySQL就不会使用索引。应该养成简化where条件的习惯,始终将索引列单独的放在比较符号的一侧;
2.2前缀索引和索引选择性
索引的选择性是指:不重复的索引值(也称为基数)和数据表的记录总数(#T)的比值,范围从1/#T到1之间。唯一索引的选择性为1。
对于BLOB、TEXT或者很长的varchar类型的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度;
2.2.3多列索引
查询时,如果使用两个单列索引进行扫描,MySQL会将结果进行合并。
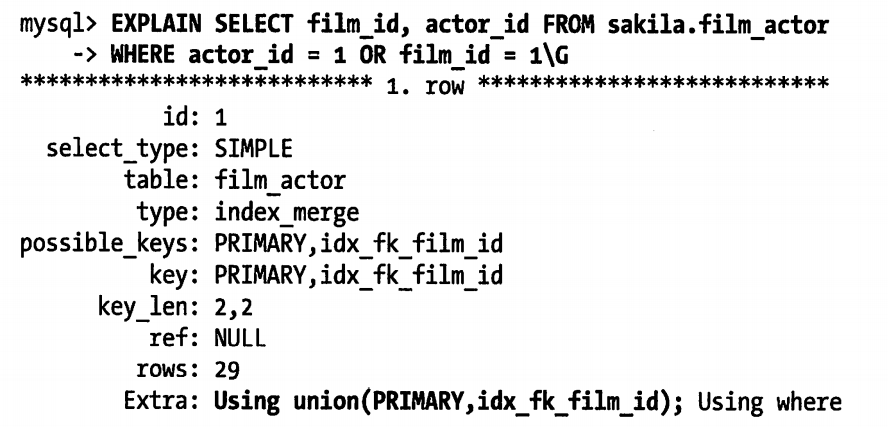
通过explain可以可到extra列的union表示索引合并;
2.2.4选择合适的索引顺序
2.2.5聚簇索引
聚簇索引不是一种单独的索引类型,而是一种数据存储方式。
Innodb的聚簇索引实际上在同一结构中保存了索引和数据行。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
优点:
①可以将相关数据保存在一起;
②访问数据更快;
③使用覆盖索引扫描的查询时,可以直接使用页节点的主键值;
缺点:
①插入速度严重依赖于插入顺序,如果不是按照主键顺序加载,速度慢;
②更新聚簇索引的代价很高;
③聚簇索引的表插入新行,或者主键更新导致移动时,可能面临“页分裂”问题;
④二级索引可能比想象的大,因为二级索引包含引用行的主键列;
⑤二级索引需要两次索引查找,而不是一次;

innodb中如果没有什么数据需要聚集,可以定义一个代理主键,最简单的方法是使用auto_increment自增列;这样可以保证数据按顺序写入,性能更好。
顺序的主键什么时候会造成更坏的结果?
对于高并发工作,在innodb中按主键自增插入会造成明显的争用。主键的上界会成为热点,另一个热点会是锁机制;如果遇到这个问题,可以更改innodb_autoinc_lock_mode参数。
innodb_autoinc_lock_mode:0;表示串行,需要等待一个插入操作提交后,才能获得自增id值;
innodb_autoinc_lock_mode:1;表示在没有批量操作时,可以马上获得自增id值,不会阻塞;
innodb_autoinc_lock_mode:2;表示完全并行,但存在批量操作时,主从数据库行记录主键值不同的问题。
2.2.6覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
2.2.7使用索引扫描来排序
MySQL有两种方式生成有序的结果:通过排序操作,通过索引顺序的扫描;如果explain的type列为index,没有出现filesort,说明使用了索引扫描的排序(Extra列的index表示覆盖索引)。
2.2.8压缩索引
使用前缀压缩来减少索引的大小,从而让更多的索引放入内存中,可以提高性能。
2.2.9冗余、重复、未使用的索引
删除之。
2.3.10in()
如果想尽可能重用索引而不是建立大量的组合索引,可以使用in()技巧来避免多种索引。
通过in(罗列可能值),增加查询的条件,从而能够使用相对应的组合索引。
2.3.11避免多个范围条件

三、总结
在选择索引和编写利用这些索引的查询时,有如下三个原则要记住:
①单行访问时很慢的。如果服务器从存储中读取一个数据块只为一行数据,那么浪费了很多工作,使用索引可以创建位置引用以提高效率;
②按顺序访问范围数据是很快的。第一顺序IO不需要磁盘寻道;第二不需要额外的排序工作;
③覆盖索引查询是很快的。如果一个索引包含了查询所需的所有列,那么存储引擎就不需要回表查找行,避免了大量的单行访问。