MySQL高级特性
一、分区表
对用户来说,分区表是一个独立的逻辑表,但是底层由多个物理子表组成。实现分区的代码实际上是对一组底层表的句柄对象的封装。对分区表的请求,都会通过句柄对象转化成对存储引擎的接口调用。
MySQL实现分区表的方式——对底层表的封装——意味着索引也是按装分区的子表定义的,没有全局索引。
分区表的限制:
①一个表最多只能有1024个分区;
②在MySQL5.1中,分区表达式必须是整数,或者返回整数的表达式。在MySQL5.5中,某些场景可以直接使用列来进行分区;
③如果分区字段中有主键或者是唯一索引的列,那么所有的主键列和唯一索引列都必须包含进来;
④分区表中无法使用外键;
1.1分区表的原理
分区表由多个底层表实现,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区。存储引擎管理分区的各个底层表和管理普通表一样,分区表的索引只是在各个底层表上各自加上一个完全相同的索引。
当分区表上执行select、insert、delete、update操作时,分区层先打开并锁住所有的底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据。虽然每个操作都会“先打开并锁住所有的底层表”,但这并不是说分区表在处理过程中是锁住全表的。如果存储引擎能够自己实现行级锁,例如InnoDB,则会在分区层释放对应表锁。
1.2分区表的类型
MySQL支持多种分区表。看到最多的是根据范围进行分区,MySQL还支持键值、哈希和列表分区。
1.3如何使用分区表
当数据量巨大时,每次查询肯定不能扫描全表。使用B-Tree索引时,除非是覆盖索引,否则数据库服务器需要根据索引扫描结果回表,查询所有符合条件的记录,这会产生大量的随机I/O。另外,索引维护的代价也非常高。
分区要做的事情是,以更粗粒度的方式,定位到需要数据的一片“区域”。在这片区域中,你可以做顺序扫描,还可以建索引。为了保证大数据量的可扩展性,一般由下面两个策略:①全量扫描数据,不需要索引;②索引数据,并分离热点。
1.4分区问题
null值会使分区过滤失效
分区表达式的值可以是null,存放在第一个分区(特殊分区)中。如果第一个分区特别大,特别是使用第一种策略,代价会非常大。
分区列和索引列不匹配
如果定义的索引列和分区列不匹配,当查询索引列(不包含分区条件)时,由于每个分区表都有独立的索引,所以需要扫描所有分区的索引。避免该问题:确保索引列和分区列匹配,或者查询条件中包含分区条件。
选择分区的成本可能很高
判断分区,这个问题的成本可能很高。因为服务器需要扫描所有的分区定义来找到正确的答案。对于大多数系统来说,100个分区是没有问题的。
打开并锁住底层表的成本可能很高
维护分区的成本可能很高
1.5查询优化
分区最大的优点就是优化器可以根据分区函数来过滤一些分区。根据粗粒度索引的优势,扫描更少的数据。
MySQL只能在使用分区函数的列本身进行比较时才能过滤分区,而不能根据表达式的值去过滤分区,即使这个表达式就是分区函数也不行。
二、视图
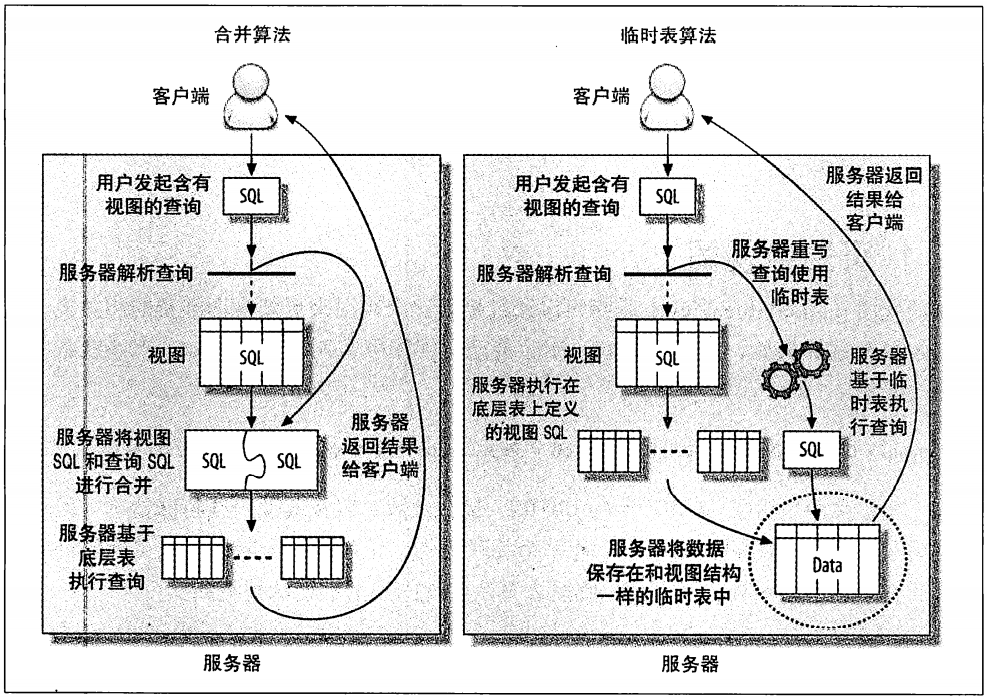
视图本身是一个虚拟表,不存放任何数据。在使用SQL语句访问视图时,它返回的数据是MySQL从其他表中生成的。
实现视图,最简单的方式是将select语句存放到临时表中。当需要访问视图的时候,直接访问这个临时表。如下:

这样会有明显的性能问题,优化器很难优化这个临时表的查询。实现视图更好的方法是,重写含有视图的查询,并将视图定义的SQL直接包含进查询的SQL
中。如下:

MySQL可以使用这两种方法中任何一种来处理视图:
2.1可更新视图
可更新视图是指可以通过更新这个视图来更新视图涉及的相关的表。
2.2视图对性能的影响
多数人认为视图不能提升性能。如果打算使用视图来提升性能,需要做比较详细的测试。即使是合并算法实现的视图也会有额外的开销,而且视图的性能很难预测。
三、外键约束
InnoDB是目前MySQL唯一支持外键的内置存储引擎。
使用外键是有成本的,比如每次外键通常要求在修改数据时,都要在另外一张表中多执行一次查找操作。虽然InnoDB强制外键使用索引,但还是无法消除这种约束检查的开销。
如果想确保两个相关表始终有一致的数据,那么使用外键比在应用程序中检查一致性的性能要高很多。
外键约束使得查询需要额外访问一些别得表,这也意味着需要额外得锁。如果向子表中写入一条记录,外键查询会让InnoDB检查对应得父表的记录,也就需要对父表进行加锁操作,来确保数据不被删除。因为没有直接访问,这也导致了锁等待和死锁情况的难以排查。有时,可以使用触发器来替代。
如果只是使用外键做约束,那么通常在应用程序里实现该约束会更好。
四、在MySQL内部存储代码
MySQL允许通过触发器、存储过程、函数的形式来存储代码。从MySQL5.1开始,还可以在定时任务中存放代码,称为“事件”。
优点:
①它在服务器内部执行,离数据最近,另外在服务器上执行可以节省带宽和延迟;
②代码复用。保证了一致性和安全性;
③简化代码的维护和版本的更新;
④提升安全,提供更细粒度的权限控制;
⑤服务器可以缓存存储过程的执行计划,减少消耗;
⑥因为在服务端部署,维护备份都在服务端完成;
⑦应用开发和数据库开发更好地分工;
缺点:
①没有好用的开发和调试工具;
②较之应用程序的代码,效率稍微差一些;
③存储代码会带来额外的复杂性;
④因为存储在服务器中,相对有安全隐患;
⑤存储过程会给数据库服务器增加额外的压力;
⑥MySQL不能控制存储程序的资源消耗,一个很小的错误,可能会把服务器拖死;
4.1存储过程和函数
MySQL的架构本身和优化器的特性使得存储代码有一些天然的限制,它的性能也一定的受限。
4.2触发器
触发器可以让你在执行insert、update、delete的时候,执行一些特定的操作。
使用触发器可以减少客户端和服务器之间的通信,所以使用触发器可以简化应用逻辑,还可以提高性能。另外,还可以用于自动更新汇总表。
需要特别注意:
①对每一个表的每一个事情,最多只能定义一个触发器;
②MySQL只支持“基于行的触发”——也就是说,触发器始终只能针对一条记录。
③触发器可能导致死锁或者锁等待。如果触发器失败,那么原来的SQL语句也会失败。
4.3事件
事件时MySQL5.1引入的一种新的代码存储方式。类似于Linux的定时任务。
五、全文索引
全文索引有着自己独特的语法。没有索引也可以工作,如果有索引效率会更高。用于全文搜索的索引有着独特的结构,帮助这类查询找到匹配的某些关键字。
下面是一个使用自然语言搜索的查询:

和普通查询不同,这类查询自动按照相似度进行排序。在使用全文索引进行排序的时候,MySQL无法再使用索引排序。所以如果不想使用文件排序,就不要使用ORDER BY语句;
在match()函数中指定的列必须和全文索引中指定的列完全相同,否则无法使用全文索引。这是因为全文索引不会记录关键字是来自哪一列的。
六、查询缓存
很多数据库产品都能够缓存查询的执行计划,对于相同类型的SQL就可以跳过SQL解析和执行计划生成阶段。但是MySQL还有另一种不同的缓存类型:缓存完成的SELECT查询结构,也就是“查询缓存”。
查询缓存系统会跟踪查询中涉及的每个表,如果这个表发生变化,那么这个表相关的所有缓存数据都将失效。
很多时候,我们还是认为应该默认关闭查询缓存。
6.1MySQL如何判断命中缓存
缓存表存放在一个引用表中,通过一个哈希值应用,这个哈希值包括:查询本身、数据库、版本等信息。任何不同都会导致缓存的不命中。
如果查询语句中包含任何的不确定函数,那么在查询缓存中是不可能找到缓存结果的。
MySQL的查询缓存可以提升性能,但也会有额外消耗:
①读查询之前必须检查是否命中缓存;
②如果这个读查询可以被缓存,那么当完成执行时,会将结果存入查询缓存,这会有额外消耗;
③写操作时,需要检查,所有有关缓存设置失效;
当一个语句修改某个表,在此事务期间,对应缓存无法查询或者保存。因此,长时间运行事务,大大降低查询缓存的命中率。
再加上,对查询缓存操作是一个加锁排他操作。无论是检查缓存是否命中,还是检查失效,都需要等待这个锁。
6.2查询缓存如何使用内存
查询缓存是完全存储在内存中。MySQL用于查询缓存的内存被分成一个个的数据块,数据块是变长的。每一个数据块中,存储自己的类型、大小和存储数据本身,还外加指向前后数据块的指针。
当服务器启动时,先初始化查询缓存需要的内存,初始是一个完整的空闲块。当有查询结果需要缓存时,MySQL先申请一块数据块用于存储,大于参数query_cache_min_res_unit的配置。因为无法预知查询结果的大小,所以至少申请该大小内存块。
因为需要先锁住空间块,然后找到合适大小的数据块。相对来说,这是一个比较慢的操作。数据存入之后,如果不够,则会再次申请,如果剩余,则会释放空闲空间。
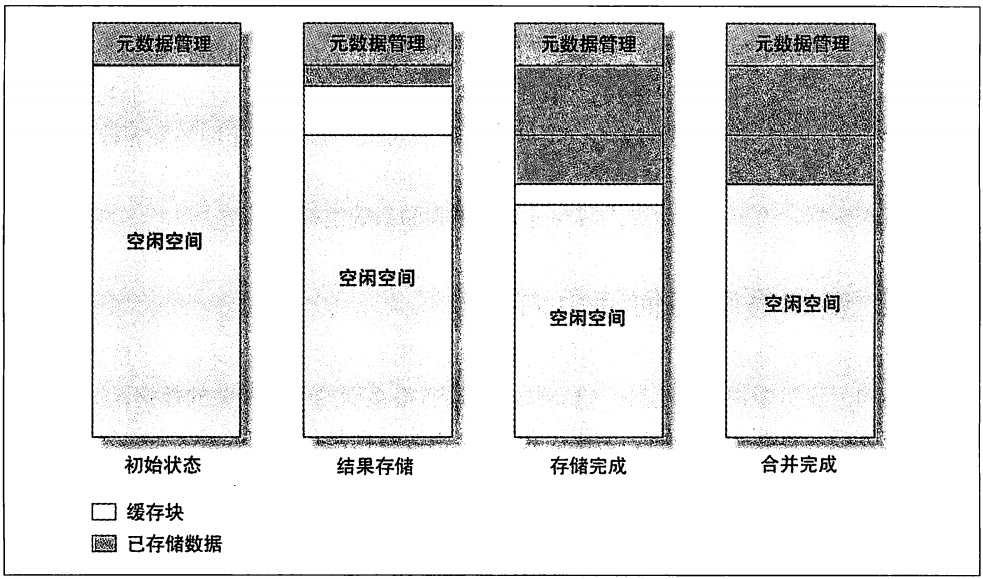
因为,每次分配内存块的大小都必须大于参数query_cache_min_res_unit,在数据块被回收后,会产生“空隙”,我们称为“碎片”。
6.3什么情况下查询缓存能发挥作用
例如,打开查询缓存可以使得一个很慢的查询变得非常快,但是也会让其他查询稍微慢一点点。有时候如果能够让某些关键的查询速度更快,稍微降低一下其他查询的速度是值得的。不过,这种情况我们推荐使用SQL_CACHE来优化对查询缓存的使用。
①配置query_cache_type,0代表不适用缓冲,1代表使用缓冲,2代表根据需要使用;
②设置1时,代表所有查询都使用缓存,如果不需要缓存,则使用如下语句:
SELECT SQL_NO_CACHE * FROM my_table WHERE …
设置2时,代表所有查询默认不需要,如果需要缓存,则使用如下语句:
SELECT SQL_CACHE * FROM my_table WHERE …
6.4InnoDB和缓存
因为InnoDB有自己的MVCC机制,所以相比其他存储引擎,交互要更加复杂。
事务是否可以访问查询缓存取决于当前事务的ID,以及对应的数据表上是否有锁。每一个InnoDB表的内存数据字典都保存了一个事务ID号,如果当前事务ID小于该事务ID,则无法访问查询缓存。如果表上有任何的锁,那么对这个表的任何查询语句都无法缓存。
当事务提交时,InnoDB持有锁,并使用当前的一个系统事务ID更新当前表的计数器。锁在一定程度上说明事务需要对表进行修改操作,当然有可能不进行修改,但如果想修改获得锁是前提条件。InnoDB将每个表的计数器设置成某个事务ID,而这个事务ID就代表了当前存在修改表的最大事务ID。